- Oracle Managed Services
Oracle Managed Service Case Study
Discover how we migrated Stripe to Oracle Cloud and then saved them time, resource and costs by managing their cloud environment.
.png?width=200&name=stripe-background-image_750x400%20(2).png)
Oracle Managed Services
- Oracle Cloud Services
Oracle Cloud Service Case Study
Discover how we deployed Oracle Cloud to solve C2C Rail's challenges.

Oracle Cloud Services
- Oracle Consulting Services
Oracle Consulting Case Study
Discover how we saved LV millions...

Oracle Consulting Services
- Oracle Application Development
Oracle APEX Case Study
Discover how we developed a feature-rich mobile tasking application for NHS York Trust, saving Doctor's time and improving patients experience.

Oracle APEX Services
- Contact Us
Predicting the Six Nations using OCI Data Science
Contents

A few weeks ago Oracle released their most advanced Machine Learning offering yet – OCI Data Science. This release coincided with two things DSP-Explorer are very interested in, Oracle OpenWorld London and the Six Nations rugby tournament.
At DSP-Explorer we have a history of using Oracle’s Machine Learning products to predict sporting events, including our blog predicting the outcome of the recent Rugby World Cup, and our presentation at Oracle OpenWorld London where we predicted the current Premier League season.
Naturally this led us to explore OCI Data Science by predicting the results of the ongoing Six Nations Championship.

To predict the Six Nations, I gathered the match scores of the games in the previous tournaments since 2004, as well as explanatory variables such as the world rankings of the nations involved, and the overall tables from previous tournaments.
My Predictions: Working With The Data
I used OCI Data Science to cleanse the data and choose which variables to use for modelling. The process progressed much more quickly than my previous experiences of setting up these predictions using other software and programming languages.
This allowed me to get straight into creating models, with the most accurate model for predicting the number of points scored in a match proving to be a ‘Nearest Neighbor’ algorithm.
When I first used this model to predict the matches in the Six Nations we got some interesting results, including a prediction that Italy would beat England for the first time in the history of the tournament! This prompted me to re-investigate the data, leading to a discovery that some team names had been muddled up in data collection.
Once I fixed this error the predictions became much more sensible, with England set to beat Italy 36-13. This demonstrates the importance of understanding your dataset – if I hadn’t realised that the original prediction seemed strange then this bug may have gone unnoticed.
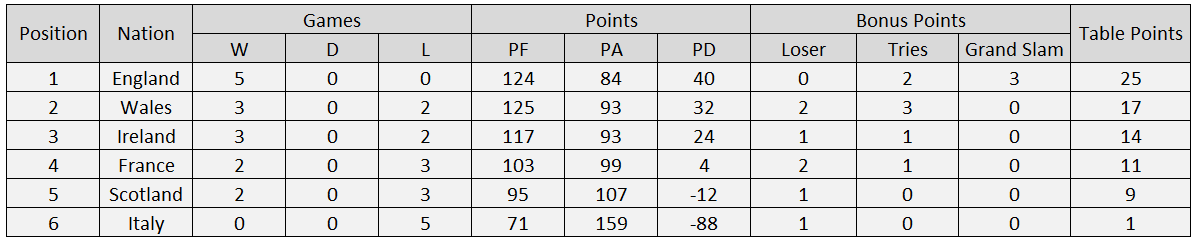 Predicted Six Nations 2020 Table
Predicted Six Nations 2020 Table
The corrected model predicted that England will achieve a Grand Slam victory, but it wasn’t to be. This prediction required them to beat France, whereas in reality France edged out England in a thrilling 24-17 match at the start of the tournament, putting France in with a very strong chance of winning overall.
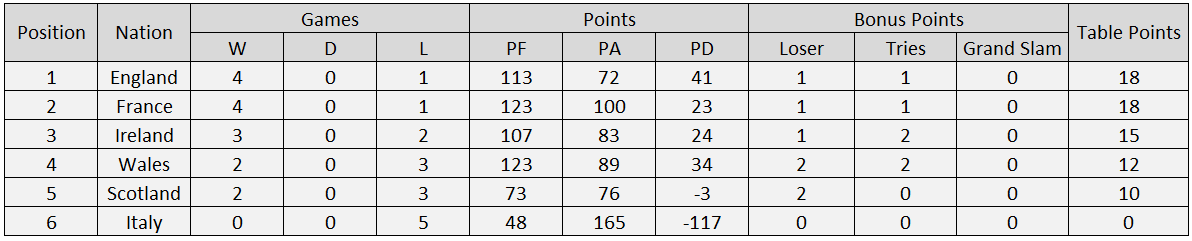 Predicated Six Nations 2020 Table (Updated after 3 rounds played)
Predicated Six Nations 2020 Table (Updated after 3 rounds played)
At the time of writing, the results of 7 out of 9 matches played have been correctly predicted. Other than England against France, the only match that received an incorrect prediction was Wales against France; I had predicted a Welsh victory, but in reality France won 27-23.
The overall success rate of these predictions brings me confidence that the current model is very accurate, and that (unfortunately for England) France are simply outperforming expectations.
Winners and Wooden Spoons
The remaining predictions state that France will beat Ireland but lose to Scotland, narrowly missing out on a Grand Slam victory in the competition. In fact, if my predictions for the remaining matches are correct then both England and France will win 4 games and lose 1, meaning the winner of the tournament will come down to bonus points. I predict England to win the tournament due to a better score difference than France.
Towards the bottom of the table the data predicts that Italy will continue to lose all their matches and ‘win’ the wooden spoon as they have 14 times in their 20 appearances in the tournament. Even if Scotland can pull off the seemingly unlikely victory against France, I predict them to finish in fifth due to Wales scoring more bonus points.

The real challenge in predicting this tournament is that there is a crucial lack of data, as the nations involved in the Six Nations usually only play competitively against each other at this tournament. Across 16 years of historical data there are less than 300 historical matches to train our machine learning models on, which is not enough data for the high level of accuracy we strive for in our models.
Using OCI Data Science
As the name implies, OCI Data Science is part of the ever-expanding Oracle Cloud Infrastructure, meaning it is well integrated with Autonomous Databases and Cloud Storage.
It is based upon the very popular open-source programming language Python. This has become a standard language for Data Science as there are many open-source libraries available, through which we can streamline the Machine Learning process and gain access to many top Machine Learning models. OCI Data Science offers access to all the standard Python libraries as well as Oracle’s own library: Accelerated Data Science (ADS).
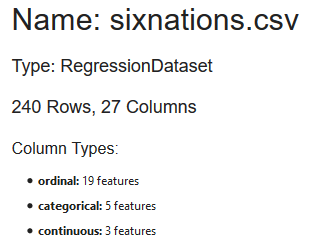
ADS also includes some really neat features to boost Data Scientist efficiency. Once I had collected my dataset I first used the ADS function show_in_notebook, which quickly produces the visualisations a data scientist needs to understand their dataset.
The first tab, Summary, gives an overview of the dataset, with the size of the data and what types of variables are involved.
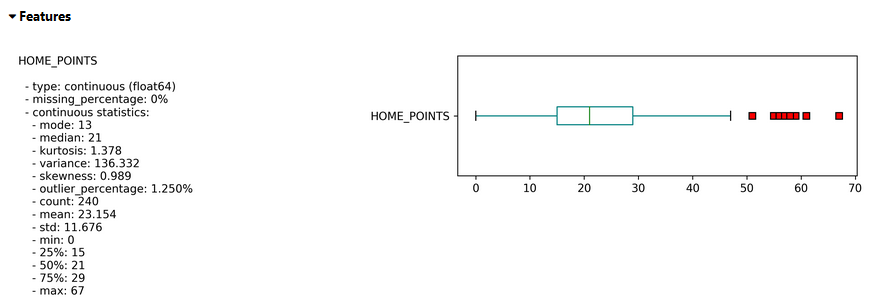
Then the Features tab breaks down each variable into all potentially useful stats, as well as showing the data in a relevant graph. The choice of graph depends upon the type of data given; we can see below that for the number of points scored by the home team (home_points) we get a box plot, whereas for the number of points a team scored in the previous years we get a bar chart.
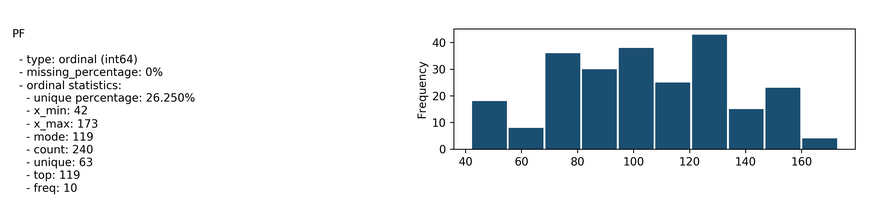
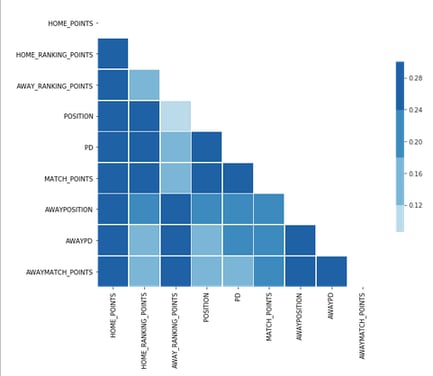
Next we have the correlations tab, which shows how correlated the variables are with each other. This is important to know as including multiple variables that provide duplicates of relevant information (eg. Match Result and Match Score) can cause a machine learning model to underperform.
Likewise, including variables which aren’t correlated with the target variable (home_points) can also cause the model to underperform.
The final tab simply shows the data.
After exploring the data with show_in_notebook we receive some automated suggestions about how to clean our dataset with the get_recommendations function. This suggests solutions to issues such as replacing/removing missing data, fixing imbalances in the dataset, and dropping variables which are too highly correlated with other variables.
These are always given as recommendations, with the final decision on implementation always taken by the user to allow use of personal knowledge to be included.
 Since my data exploration and cleansing process was sped up by the ADS package, I could more quickly progress to modelling the data. ADS is once again very useful here, as AutoML automatically trains and tests hundreds of models without having to utilise the extra manpower that would normally be required to complete these tasks.
Since my data exploration and cleansing process was sped up by the ADS package, I could more quickly progress to modelling the data. ADS is once again very useful here, as AutoML automatically trains and tests hundreds of models without having to utilise the extra manpower that would normally be required to complete these tasks.
This is a big advance on Oracle’s previous offerings, as there are now many more models available and we can find the best of these models much more quickly, which allows us to gain quicker insights.
If our models are not performing as well as we would like then we return to the original dataset and try to improve it; in this case I could include more explanatory variables that might have previously been missed, such as how well individual players are performing in the build-up to the tournament.
Final Thoughts
Considering the challenges posed by the lack of data in this situation I am impressed by the accuracy of the predictions I have attained through OCI Data Science, and even more impressed by how streamlined the process felt. OCI Data Science will certainly be added to our regular toolkit here at DSP as we continue to roll out our Machine Learning Consulting services.
As an Englishman I am now going to sit back and see if Eddie Jones’s men can match my predictions and win the Six Nations 2020, starting with a 23-17 victory over Wales this Saturday.