- Services

Getting to know us
- Industries
Recent case study:
Oracle EBS Cloud Deployment
Consolidating and Migrating assets into Oracle Cloud Infrastructure.
.png?width=250&name=stonewater-logo%20(1).png)
Most Visited Pages
-
- Resources
DSP-Explorer acquires leading Oracle Applications Managed Services Provider, Claremont, to further extend its data management capabilities.

Resources
- Contact us
OCI Document Understanding
Contents
Introduction
Oracle recently announced their new Document Understanding feature in OCI. In this blog, I will be looking into this feature and considering its practical application in conjunction with APEX.
The concept of ‘Document Understanding’ broadly covers a few areas:
- Automatic recognition and digitisation of text in an image format – i.e. what we would traditionally refer OCR (Optical Character Recognition)
- Classification of documents into predefined categories based on features of a document, such as textual content and item positioning
- Data extraction – the ability to identify and extract data items within a document, either as specific key-value pairs, lines or text, or tabular data. Metadata relating to such items, like positioning, can also be extracted.
The features described above, therefore, have the potential to help automate data-entry processes, as well as allow digital categorisation and searching of large numbers of documents.
Review
As this is an Oracle Cloud Infrastructure (OCI) feature, it is accessible via an OCI console. Use of the Document Understanding service is chargeable, but you can see how it works in a free tier account, available on the menu via Analytics and AI -> Document Understanding:
The overview page contains a large amount of information about this topic, including links to useful videos.
The rest of the module is split into various modes with which you can analyse a document image. Each section provides sample documents, but I thought I’d try my own, so I asked ChatGPT to throw together a pretend invoice document with a fair amount of text in it, which I saved as a pdf.
Text Extraction
Text Extraction is perhaps the most simple concept to understand at a basic level.
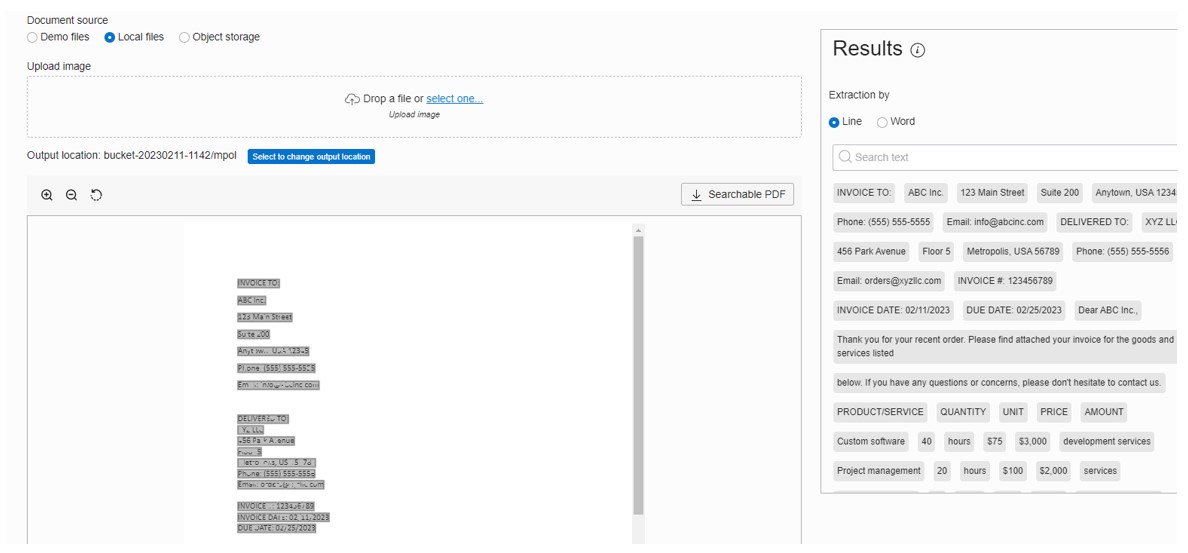
I selected ‘Local files’ and then uploaded my sample document. After a few seconds, the results came back – I had opted to extract by line, so each line within the document was saved as a separate data item. You can see an image of the document in the left-hand pane, with the results on the right.
On the right pane, you can also view the request JSON:

As well as the generated response:

With this information, you can start to see how you would extract this data via the rest API into, for example, an APEX application.
Table Extraction
Next, I tried the table extraction method. The document I created had a table embedded in the text.
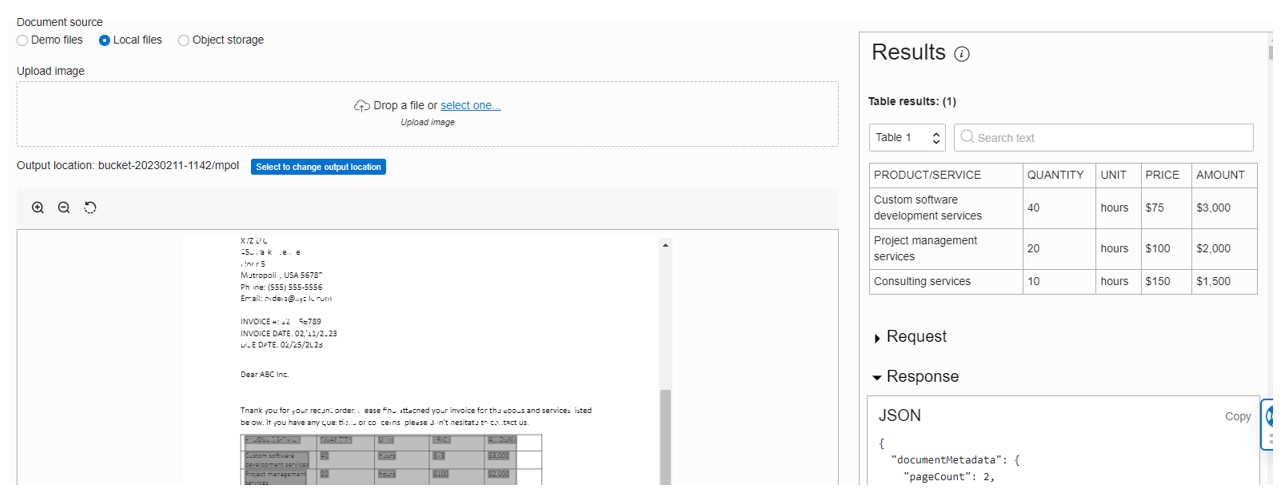
The analyser recognised the table and regenerated the data it held seamlessly.
Key value extraction
Then I tried the Key value extraction method. This uses a pre-trained model of common document types, such as invoices, receipts, passports etc, to identify the type of document and then extract key-value pairs from the results. My sample document was randomly thrown together, but the analyser still identified it as an invoice, with a confidence of 50%.
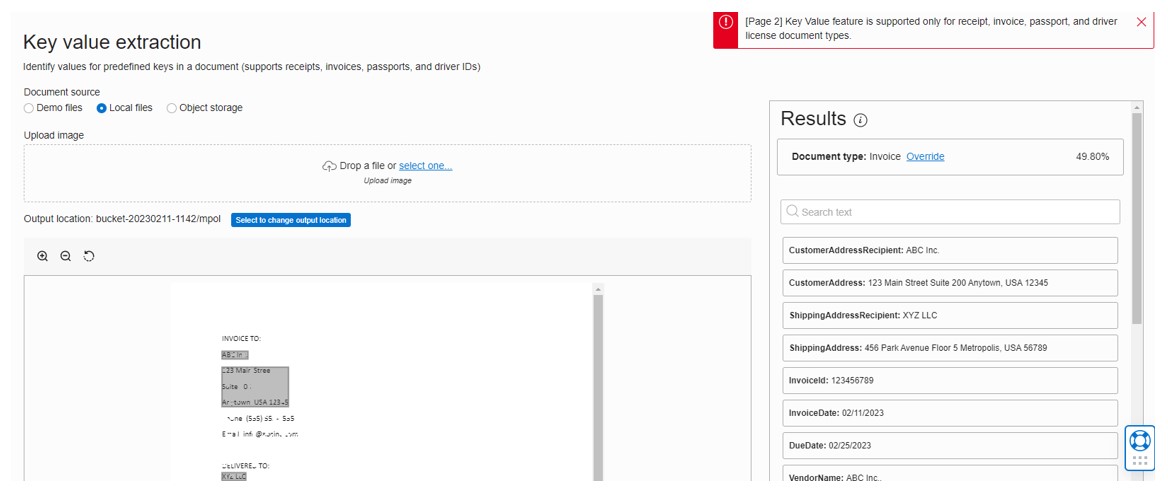
As you can see, the analyser also picked out a number of the other data items and matched them to some predefined data types. Each of these results is provided with a confidence percentage to allow you to determine at what threshold you would accept the analysis.
I thought I would also see how accurate the analysis of another type of document was, so I uploaded my driving licence (I understand this only currently works for US and UK licenses):
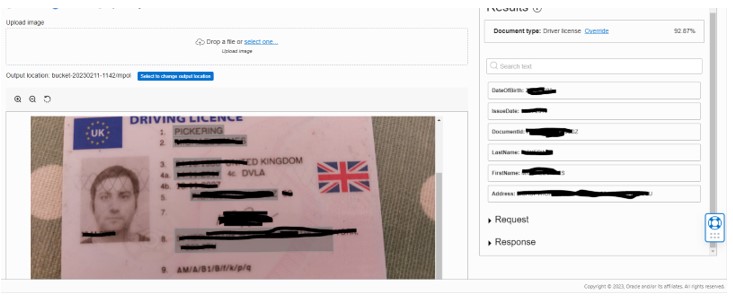
Suffice it to say it very accurately picked out the most significant details and, of course, the fact that it was a driving licence, despite it not being the clearest photo.
More advanced functionality is also available to allow users to define their own documents, beyond the pre-trained document types provided by Oracle.
Document Classification
As a final task for the sample document, I used the document classification method to identify my document type, and it was pretty confident that it was an invoice: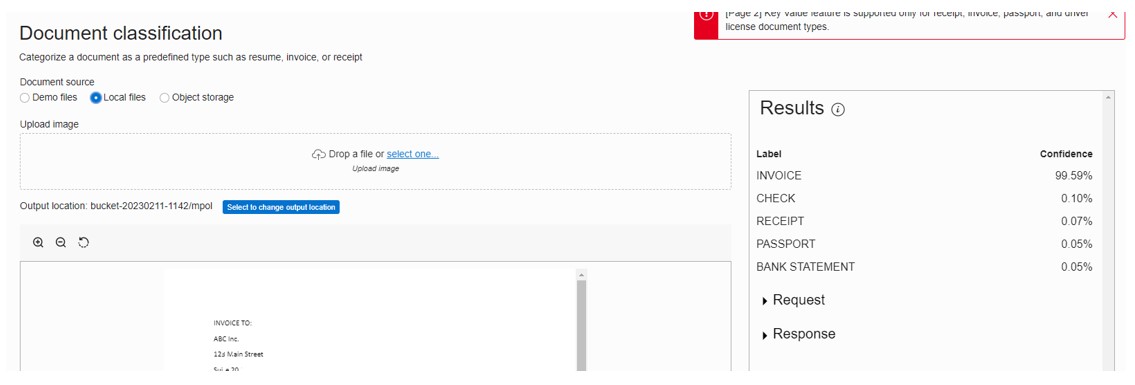
Practical Application
To tie everything together from an APEX application development perspective, it would be easy to handle document uploads to an OCI bucket, then use the Document Understanding API to analyse the document(s) in the various ways described above and then return the results via JSON to be displayed either directly in the APEX app or rather save results in a table for interpretation via an APEX application.
APEX 22.2 introduced the Application Search functionality, which allows you to set up a search engine-style page and tie it to a SQL-based data source. One could quite quickly set up an application that allows users to upload and analyse digital documents, perhaps storing each line of text in a row in a database table, then use Application Search to let the user search any line of text, then download any matching files.
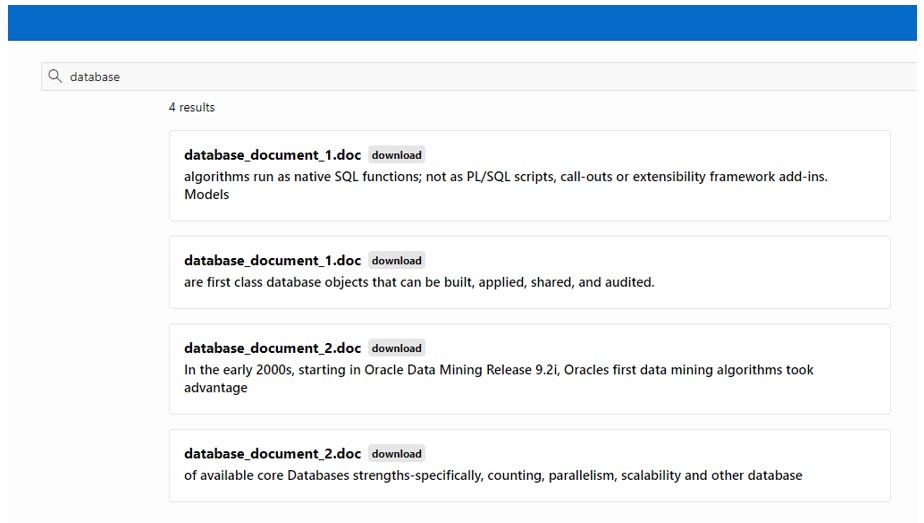
The potential for the development of a variety of applications, which could combine the power of Oracle Document Understanding and APEX’s ability to present the results in an easily accessible, web-friendly manner, is vast.
Organisations that can benefit from this functionality include those that:
- create or receive invoices and receipts (i.e. most organisations)
- have a large amount of historic documentation and wish to categorise/catalogue those documents
- wish to digitise the content of historic paper/digital documents and make the text searchable
Conclusion
OCI Document Understanding is an undeniably powerful tool and one that has the potential to open up new avenues for Oracle-based application development.
For more information, check out our OCI and APEX services, and if you liked this blog, check out our other APEX blogs here.
Contact us today to discuss how document understanding could work for you.