- Services

Getting to know us
- Industries
Recent case study:
Oracle EBS Cloud Deployment
Consolidating and Migrating assets into Oracle Cloud Infrastructure.
.png?width=250&name=stonewater-logo%20(1).png)
Most Visited Pages
-
- Resources
DSP-Explorer acquires leading Oracle Applications Managed Services Provider, Claremont, to further extend its data management capabilities.

Resources
- Contact us
Liquibase and Flyway: Using Database versioning tools for APEX database projects.
Contents
As an APEX developer that used to be an Oracle Forms developer, my approach to releasing front-end code (APEX apps) and backend code (the plsql packages and triggers that support the application) has always been pretty fixed and clear. You write the application in the builder, export it and save it in version control. You maintain your packages etc in a file in a folder linked to a version-controlled repository and compile the object against the database.
The element of Oracle application development that’s always been a little unintuitive for me is the DDL side of things. On one hand, DDL during a dev project will evolve over time in much the same way as business logic in code and therefore can be treated in much the same way. E.g. you make a change to a table, you add a column to the table script in your repo. Alternatively, you make a change to some config data and you create or modify insert/update scripts accordingly. However, for me at least, there’s always been an element of complexity and, for want of a better word, faff, about maintaining scripts in this way. Possibly because unlike maintaining code, the process of updating DML and data is slightly more removed from the main thrust of app development. Changes can easily get lost without good discipline in a multi-developer team, mainly because the act of making the change (e.g. adding a column to a table) requires another step to keep everything up to date, whereas changing (e.g.) a package function is both the functional and scripted change because I simply updated my version script from the repo and compiled it.
As such, I did some digging into ways of formalising the DDL and Data processes. I examined a couple of tools – Flyway and Liquibase, to see whether they would add value to ongoing and future APEX development projects.
- Both of these tools allow versioned control and deployment of Database schema and data.
- Both basic versions are free to use.
Additionally, I examined using the integrated version of Liquibase in SQLcl which crucially allows the generation of a baseline version from an existing database.
Both tools allow you to version your schema and data changes so that you can track what was changed and when. Both allow you to deploy the latest versions of code to other environments.
Flyway
I downloaded the community, command line version of Flyway from https://flywaydb.org/ and was very quickly able to start generating DDL and creating different migrations for my schema and data.
There is a basic folder structure from which you can execute Flyway functions:
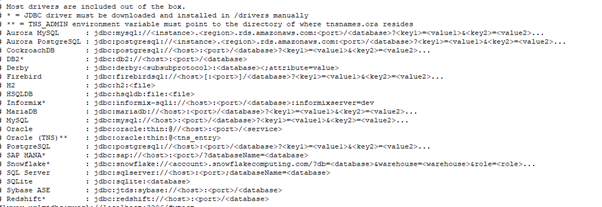
The ‘conf’ folder contains a config file that allows you to set up your database connection, with relevant user/password etc… it helpfully contains the connection string format for most types of database:
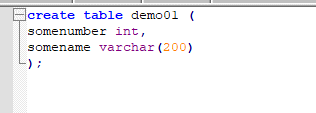
I then created some basic ddl and data files in the ‘sql’ folder:
V1__Create_demo01.sql:
V2__demo01_data.sql:

I now simply open a command window, navigate to my flyway folder and run ‘flyway migrate’

This performs the migration, checking what versions (based on the V… in the file name) have already been installed and installs anything new.

In my database I now have the simple table created and data inserted.
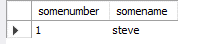
The history of migrations is also available to me in the flyway_schema_history table:

By following the versioning format I can keep adding new files to the project and then deploy (potentially to multiple environments, dev/test etc) as necessary. In order for this to work on a project, there would probably need to be a ‘gatekeeper’ that handles all such scripts and deploys in one go, rather than each developer making their own changes. But if changes are handled in such a way, it does provide a greater level of control and auditing over the process of changing schema objects and data.
Liquibase
The community, command line version of Liquibase follows very similar principles to flyway. They both use a simple script migration process to create migration versions in the target database. Liquibase differs slightly in that rather than creating multiple files, a master ‘changelog’ is used to promote the data, with versioned entries reference within that single file (albeit with the ability to include other files within the master).
Liquibase – via SQLcl
While I was doing some research on Liquibase, a colleague pointed me to the Liquibase capabilities within SQLcl. Up to this point, I was impressed by the ability of Flyway and Liquibase to allow you to create new database projects and develop a method of version control for them, but I hadn’t got to grips with whether it was possible to use such a tool halfway through a project – i.e. get the current state of the database as my ‘V1’ and go from there. The Liquibase capability within SQLcl allows you to do just that, by running commands that export your schema and data into XML files and then redeploying them to another environment as a single version. Obviously being able to do this has potentially massive benefits for the deployment of many different types of projects.
Within SCLcl I first brought up Liquibase help:
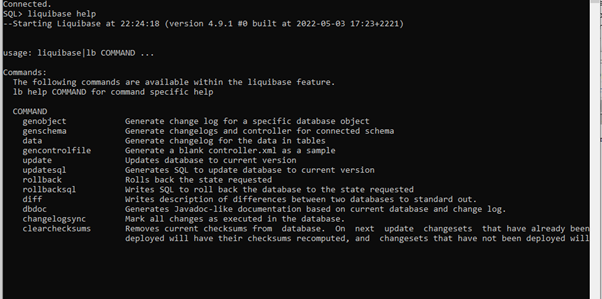
This details the various different commands you can use. In this example, I was connected to a database that had an existing schema, that related to an APEX application that had been in use for some time. My task was the move the application/database and data to a newer environment.
By running ‘lb genschema’, I was able to generate the entire schema as a series of XML files. In turn, these files were referenced in a file (generated automatically) called controller.xml:
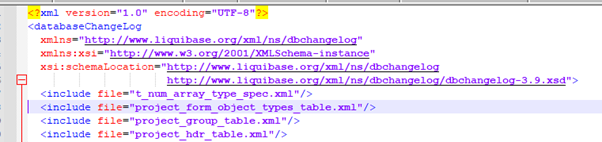
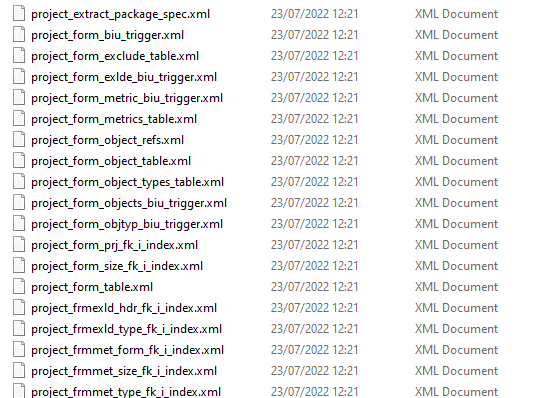
All files are created in the working directory of SQLcl itself.
In order to deploy all these objects to a new environment, I simply had to connect to the target environment in SQLcl and run another Liquibase command: lb update -changlog controller.xml (i.e. controller.xml being the migration master file created previously).

The DDL was then created straightaway in my new environment, complete with logs for each change/file uploaded in the (automatically created) databasechangelog table:


Database versioning tools such as Liquibase and Flyway offer a powerful solution for maintaining DDL objects and data during development projects. Discipline is, of course, still required: the effectiveness of these products will only be realised if their use is closely controlled. It is therefore a decision point early on in a project in terms of how many resources might be needed to administer these processes vs the gains to the project for doing so. The ability to quickly load schema changes into an environment and keep a record of them is certainly appealing, and being able to snapshot the state of the existing environment gives a very powerful tool for version control and deployment.
If you would like to speak to one of our Oracle APEX experts, get in touch through enquiries@dsp.co.uk or book a meeting...
