- Services

Getting to know us
- Industries
Recent case study:
Oracle EBS Cloud Deployment
Consolidating and Migrating assets into Oracle Cloud Infrastructure.
.png?width=250&name=stonewater-logo%20(1).png)
Most Visited Pages
-
- Resources
DSP-Explorer acquires leading Oracle Applications Managed Services Provider, Claremont, to further extend its data management capabilities.

Resources
- Contact us
AI Makes Big Prediction for 2021 EUROs
Contents
Who does AI predict will win the EUROs? Can I use AI to make money on bets? Why is it so difficult to make accurate predictions in Football? These are some of the key questions I’ll be answering in this blog post, along with explaining how a Hybrid Machine Learning Model developed by a global team of football and machine learning enthusiasts aims to make an exciting prediction for the 2021 EUFA EUROs.
If you’re just here for the final prediction, you’re in luck – I’ll save the in-depth analysis for last and get straight to the meat and potatoes, but before you read on check out our in-house AI Services here.
The Prediction
By combining three robust statistical methods for forecasting football results (team ability ranking, plus-minus player ratings, and bookmaker consensus) along with several other predictors and using a random forest model, a team of German and Belgian statisticians, mathematicians, and sports scientists have made a frankly heart-breaking prediction: neither of their home countries will be receiving the trophy.
Based on this machine learning algorithm and taking into consideration the match results we already have England are most likely to win! It’s coming home.
The model’s predictions are outlined below in a helpful visualisation (credit here). You can see that France was predicted most likely to win, followed closely by England and then Spain, yet in a result that no one would have predicted Switzerland knocked France out of the running for finals in penalties, which leaves England as the predicted champions. Incidentally, if you had bet on this outcome, you would have made 6x your investment.
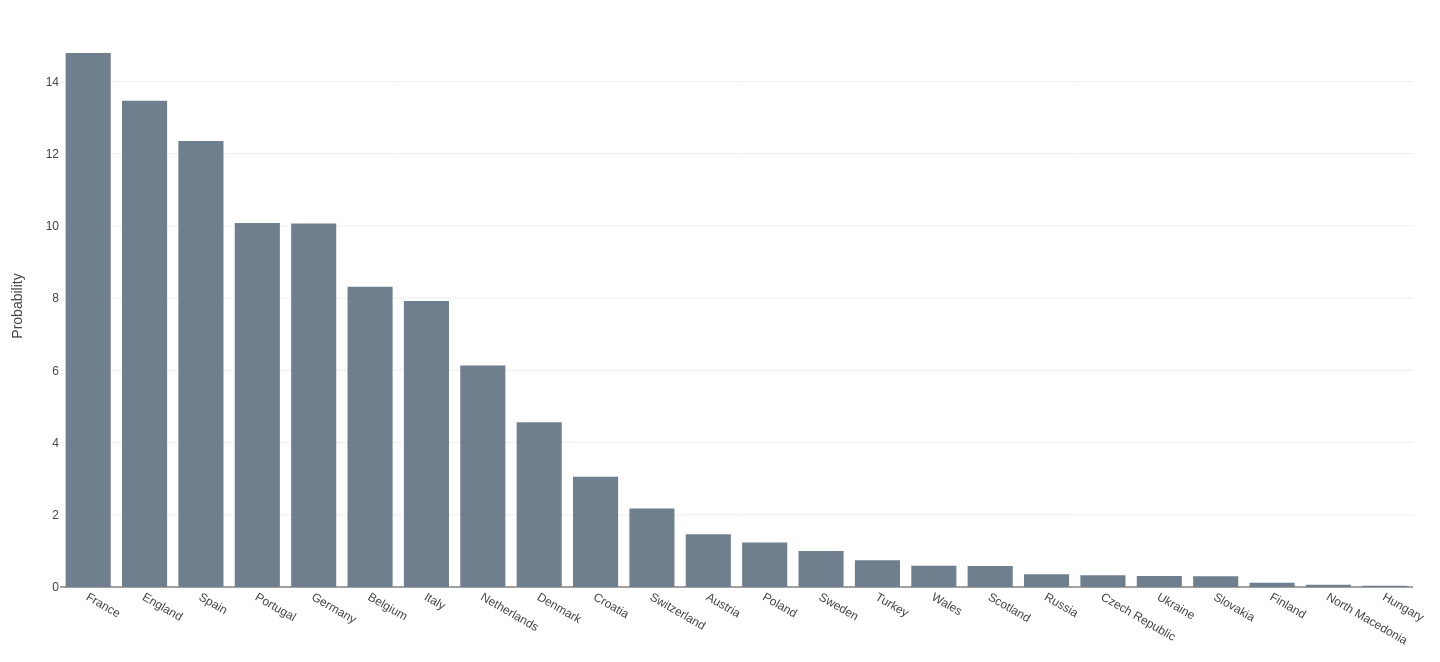
The Machine Learning Model
As I have explained above, the model which Groll et al. developed in order to make this prediction used a random forest learner to combine the three well-established forecasting methods with other team-specific statistics and country-specific socio-economic factors. As a result we have a forecast for who will win, and we can also find out which of these variables is most strongly correlated with a winning team.
Ability Ranking from Historical Data
The goal of this method is to assign a strength parameter to each of the teams based upon their historical match data from the last eight years. Using this data the team fitted a bivariate Poisson model to the number of goals scored by both teams in every match, achieving a strength parameter for every game played. These scores are then weighted using an exponential decay function which results in more recent games having more importance than those played in the past. These strength parameters can then be used to make predictions on any particular lineup.
Plus-Minus Player Ratings
This method aims to rank every player on the pitch by working out the weights of a clever linear regression equation which is defined by the goal difference observed during each segment of a match, where the end point of a segment is defined by player substitutions. By calculating the goal difference during a match segment, and considering all of the players present on the pitch, as well as accounting for other variables such as a home-field advantage, red cards handed out, player’s ages, etc., the team established a plus-minus rating for all of the players that will be present during the 2021 EUROs, which is defined as the average plus-minus rating for each player across the previous 8 years of historical data. Also taken into account in the final model are players ranked as important by the plus-minus model who are missing during a particular match.
Bookmaker Consensus Model
The final statistical method for predicting sporting outcomes is to take the odds provided by 19 global bookmakers, the idea being if the bookmaker’s profit margin can be accounted for you can average the predictions of experts to come to a consensus. This method makes the assumption that bookmakers have a constant profit margin assigned to every game, since the problem would be intractable if we considered variable profit margins. The median profit margin for the 19 bookmakers was 17.3%, not a bad business to be in if you ask me.
After re-adjusting for these profit margins, since bookmakers adjust their true opinion in their favour before providing the odds to the public, they are then converted to a logit scale (which maps probability values from [0, 1] to real numbers [-∞, ∞]) before averaging, and then converting back to the probabilistic scale. These odds are then used to infer the strength of the contenders (1 – odds = contender strength), and then used to simulate 100,000 tournaments of pairwise matchups so that the simulated winning probabilities for each team are similar to that of the bookmaker’s odds. This in turn removes the effects of a tournament draw, which reduces the complexity of the problem.
Additional Predictors
Aside from these well established statistical means of predicting football outcomes, other team-specific factors and socio-economic factors were also used in the prediction. These are: GDP per capita, country’s population, two home advantage variables (indicating whether the national team is a hosting country, or if the team is from a neighbouring country of the host), sportive factors (market value, FIFA ranking, UEFA points, UEFA starting places), several variables indicating the structure of the team, factors describing the team’s coach (coach age, if they have the same nationality as the team), and finally a dummy variable indicating whether a certain matchup is a knockout game, as it is reasonable to assume that teams will play more cautiously in such games.
Model Performance
The research team then tested several machine learning models against one another using this dataset: ranger random forest, conditional random forest, extreme gradient boosting, and lasso Poisson regression. They then compared the results to the bookmakers' performance over the previous four UEFA EUROs. This was done by means of cross validation, which is to take three out of four of the EUFAs to use as a training set for fitting the models. The sample left out is then used to test each of the models' performance, and this is repeated until all EUFAs have been used as a testing set and the results are averaged.
The three metrics the team measured their model by are the multinomial likelihood (the probability of a model making a correct prediction, higher is better), the classification rate (rate of correct classifications, higher is better), and the rank probability score (RPS, a measure of error, lower is better). The results can be seen below:
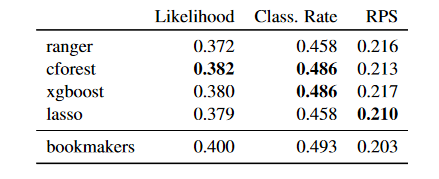
It appears as though the bookmakers always win! Nevertheless, the conditional forest method has the most positive results, which makes it the model of choice. With 24 teams participating, if you were to select a team at random to win the Euros you would be looking at a 1/24 chance or 4.2% chance of selecting correctly, so at 48.6% classification rate this model is much better than random chance, and extremely close to the bookmakers accuracy at 49.3%.
Why Can’t I Bet Using AI?
This is all a bit of fun of course, but a word of warning before you run off to the bookies’ with AI-driven odds for Saturday’s game. You’ve probably heard the saying ‘the house always wins’, and this is true with all methods of betting. In a Darwinian sense, any game where the house doesn’t win won’t produce a profit, and therefore that form of gambling will cease to exist.
Long story short, bookmakers will use their own machine learning models to verify the odds they provide on a match. Any model that’s independently developed will likely not be better than those developed from the heavy investment of the gambling industry; back in 1984 it was possible for the likes of Bill Benter to develop an algorithm that won him over $1million on horse racing, but these days statistical analysis is a universally recognised field. As such you’d find it tough to beat the cutting edge R&D that’s taking place in order to make a profit on sporting bets.
Why Sports Predictions are Difficult
The difficulty of fitting a model to data, or getting AI to perform a prediction or task, is dependant upon how complex that task is. A rudimentary way to think of complexity is to imagine the number of permutations a particular problem contains: for example, chess seems like a much less complex game to model due to the rules, the pieces, and the number of spaces on the board, as opposed to football which depends on many more factors that are difficult to even imagine. In a game of chess, after each player has had 5 turns there are 69,352,859,712,417 possible games or permutations that could have been played, and whilst that is a considerable number, it’s a problem referred to as ‘tractable’ in statistics. We have a firm definition of which games are legal, so while it may require a lot of computing power we can still fit a model to play ideal games.
On the other hand, football isn’t much of a tractable game. The research I outlined above has made a very good attempt at making it a tractable problem by cleverly defining metrics which measure the abilities of the teams, but it’s hard to imagine that we will ever come to a comprehensive definition of all of the defining factors that influence a game of footie. Maybe that’s why it’s more fun to watch than chess!
If you're interested in reading more predictions you can check out our blog post from last year's rugby world cup. Please get in touch with our experts to find out more about our in-house AI services or book a meeting...
