- Oracle Managed Services
Oracle Managed Service Case Study
Discover how we migrated Stripe to Oracle Cloud and then saved them time, resource and costs by managing their cloud environment.
.png?width=200&name=stripe-background-image_750x400%20(2).png)
Oracle Managed Services
- Oracle Cloud Services
Oracle Cloud Service Case Study
Discover how we deployed Oracle Cloud to solve C2C Rail's challenges.

Oracle Cloud Services
- Oracle Consulting Services
Oracle Consulting Case Study
Discover how we saved LV millions...

Oracle Consulting Services
- Oracle Application Development
Oracle APEX Case Study
Discover how we developed a feature-rich mobile tasking application for NHS York Trust, saving Doctor's time and improving patients experience.

Oracle APEX Services
- Contact Us
Disaster Recovery Testing in Oracle Cloud
Contents
We don’t need to test DR in the cloud! Do we?
Most reading this will likely agree that cloud computing is here to stay and are familiar with many of the key benefits that are driving more and more organisations into adopting a cloud computing model for their mission-critical applications. The reduction or almost total elimination of the procurement cycle, the ability to rapidly provision environments and to scale up and scale down with demand and then only paying for what you need and use are some of the obvious ones. However, there are many other benefits that don’t always make the headlines or make it into a cloud sales pitch. DSP-Explorer can help you understand and realise some of these additional benefits and features to help maximise your cloud investments. For example, how often does “Simplify DR testing” feature as a selling point for cloud? Given the importance of Disaster Recovery (DR) testing and often the reticence or at least challenges with it, perhaps it should!
Disaster Recovery (DR) means different things to different folks. The distinction between high availability (HA) and DR can be blurry. One organisation’s HA may be another’s DR. Irrespective of such cloud features like data replication across availability domains (ADs) or cloud regions or active/active clusters with multiple inherent layers of redundancy and resiliency, the ability to take and secure backups and have confidence they can be restored must, with few exceptions, remain as the foundation of any DR or Business Continuity (BC) plan (BCP). It might be easy to think of the multi-layer resiliency and redundancy underpinning modern cloud infrastructures and think backups may be a thing of the past but this would be wrong. One just needs to look at the malicious destruction, hijacking, corruption or encryption of data from cyber-attacks which may only be countered by recovery from historic or off-line backups for one to realise backups remains vital. After such an attack, the redundancy and resiliency provided by the underlying cloud infrastructure for what was your data is now merely providing high availability to what may ultimately just be a useless collection of encoded 1’s and 0’s. Whilst the ideal outcome here is the undoing of the malicious actions in-situ and full recovery of data, it’s possible and in some situations likely, this predicament may only be escaped by restoring from backups. And it’s not just wanton and malicious destruction or corruption of data as per this example either. There are numerous scenarios where backups may play an important role in recovery such as the accidental deletion of critical data by a legitimate and well-meaning application user that goes unnoticed for some period of time. Backups remain important – even in cloud – it’s just the method of taking them and testing that has changed. As we say here at DSP-Explorer, it’s always better to have “too many” backups that you never need than not having the one backup you do.
Historically, in a traditional on-premise model, backups would have typically been tape backups transported off-site and stored securely. Whilst tape backup technology is, understandably, not exposed by cloud providers to us as consumers of cloud services, the same paradigms and strategies that off-site tape storage offered are still very much applicable to cloud hosted environments. Oracle’s cloud offering - Oracle Cloud Infrastructure (OCI) – offers such features as block storage backups, object storage, archive storage and cross-region backups and replication, when implemented appropriately, can satisfy any DR and BC requirement.
Backups are of course integral but they are only part of the puzzle. The ability to restore those backups to produce a useable system is of course complementary and equally important. Clearly stating the obvious, but a backup that never happened or that cannot be restored from or does not reinstate an application or service really isn’t a backup. As such, it’s important to regularly perform test restores and furthermore, confirm the resulting application or database is valid and useable. Before continuing, it's worth stating that this blog makes no pretence that testing restores could or should be considered as fully testing DR procedures or BC plans. DR procedures and BC plans necessarily should cover a multitude of scenarios and areas - not all of which are technical it should be noted – with testing restores as just one key aspect. The focus of this blog specifically, however, is the testing of restores from backup in an OCI setting and therefore references to DR testing throughout should be read with this context in mind.
Whilst there’s almost universal agreement that regularly testing DR is a good thing, doing so is often “easier said than done”. There are many reasons (excuses?) given as to why testing DR remains on the list of “things to do” but happens too infrequently or perhaps never. Many of you will be familiar with or perhaps (understandably) use some of these reasons below:
- Time and Effort Required and Competing Priorities: Planning DR testing takes months - and that doesn’t include the time to actually do the restores and application testing - we simply don’t have the resource to do it alongside our other priorities – you know, those other priorities that produce an immediate business benefit!
- Potential Risk to Production Systems: DR was tested last year but when one of the recovered systems was started it unexpectedly interfaced with our production systems causing data corruption and duplication and sent invoices and emails to customers. It caused embarrassment and loss of confidence from our customers and took weeks to resolve.
- Rumour and Myth: There’s a rumour that DR was tested years ago and apparently it caused all kinds of issues because a restored DR server had the same IP address as a production server. No one from that time works here now and so without knowing exactly what happened, everyone is nervous about “trying again”.
- Complexity and Validity: We can only restore a subset of applications and databases, and we must perform manual reconfigurations of host names, IP addresses and connectivity etc. to make the applications useable for testing and also ring-fencing them so as not to interact with operational production systems or external entities. In fact, there’s so much reconfiguration required and functionality that knowingly cannot be tested, there’s a concern it’s not a valid test.
There are likely many more reasons why DR is not tested as often as it should be. It’s important to acknowledge that the above are very real and valid concerns. They are not without basis.
Indeed, DR testing does not provide an immediate tangible business benefit. It’s comparable to an insurance policy. Just as insurance is a mere expense with no real tangible benefit until such time that something bad happens and a claim is necessary, so too is DR testing - specifically the ability to successfully invoke DR procedures and BC plans - a consumer of both time and resource without tangible business benefit. Until that is, something bad happens. And so, it’s perhaps easy to understand why allocating time and resources to undertake DR planning and testing can struggle to compete with other business priorities. The concerns about applications and databases restored for DR testing inadvertently interacting with production systems or needing to reconfigure them before testing are real and valid. We all know that a server restored and having the same IP address as a production server can wreak havoc and result in often-difficult-to-diagnose unplanned production downtime. Additionally, for those organisations that do test DR, how many of these tests were successful? How many DR tests, despite being regarded as a success, consumed so much time from the IT department and application users that just the thought of repeating them regularly is exhausting? The concerns about a restored system interacting inadvertently with production causing data corruption or duplication or unwanted, and frankly embarrassing interaction with customers and third parties too are real and valid… primarily because it does happen… a lot!
OCI offers features and options to address all of the concerns.
For the very same reasons that OCI offers rapid provisioning of (production) environments, so to the same for DR. DR environments can be rapidly provisioned and will incur costs only for the relatively short period of time they are required. Compare that to on-premise where there may be a requirement to have procured sufficient compute hardware in advance to support DR testing that may only be needed for a few weeks per year and then remains idle for the remainder. Within OCI, once DR testing is complete and signed-off, the DR environment can immediately be decommissioned thus avoiding unnecessary costs. Of course, this doesn’t apply to a warm or hot DR environment or a DR environment participating in an active/active arrangement as these are examples of DR environments that must persist. However, it would still apply to their complementary though temporary DR environments created to facilitate any testing of restores. As already indicated through examples earlier, having warm/hot/standby DR environments is not sufficient to preclude the potential need to rely on restores from backups in various recovery scenarios. As such, even when such warm/hot/standby DR environments exist, backups and restores remain important components of a DR strategy.
The fears and concerns that lead to thoughts of ring-fencing DR environments so as not to interfere with production systems or reconfiguration before testing can easily be allayed with OCI. Within an OCI tenancy, two or more Virtual Cloud Networks (VCNs), with identical or overlapping IP address ranges, can co-exist without conflict and by default, without the ability for communication to occur between them. In the screenshot below, two separate yet identical networks are shown – one being the production network (vcn01-production) and the other created specifically for DR purposes (vcn02-dr). As highlighted, both networks exist with an identical IP address range (192.168.0.0/24) and DNS Domain Name (vcn01production.oraclevcn.com) configuration.

By default, OCI employs a “deny-all” policy with respect to network communication. In the example shown, for reasons that won’t be detailed here, it’s actually difficult to configure these two networks to communicate with each other even if that was the desire. Accidental, inadvertent or unintentional communication between the two simply cannot happen. From a security perspective, OCI’s default deny-all posture is a good thing and in this DR scenario, it is no exception. Significantly, the DR network created identically to the production network now facilitates restores of VMs and other resources from backups taken of production resources without the need to perform reconfiguration of such things as IP addresses, hostnames, DNS configuration etc. and importantly, without introducing risk by not having done so. This scenario – two identical yet segregated networks – in an on-premise setting is typically difficult to construct. In OCI, it’s just a couple of clicks. Additionally, all this with the peace of mind that by default resources created or restored onto the DR network cannot interact either with the production network or external customers and third parties. Should there be a requirement for specific access from the DR network to other networks or the outside world this can be established, but to minimise the risk of doing so, should only be undertaken by following a carefully considered and methodical approach.
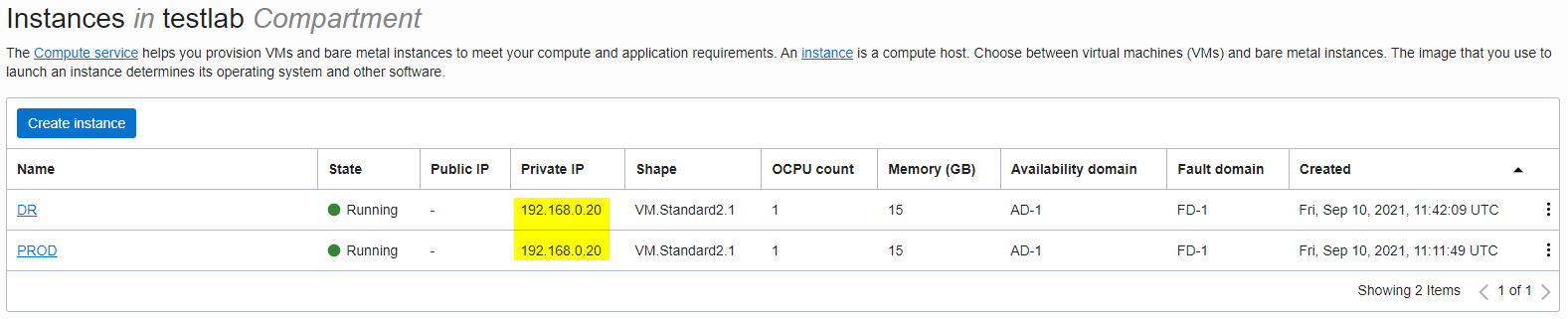
Once the DR network exists, a virtual machine (VM) – in this example named “DR” – can now be restored on to it from a backup of the “PROD” VM, as shown in the screenshot below. And in case you are wondering, yes, a backup of a VM or database system that’s on the production network can trivially be restored on to a different, and in this case identical, network. Because the “DR” VM has been restored onto an identical, yet completely segregated network, its configuration, even its IP address, can remain identical to that of the “PROD” VM from which it was restored. No reconfiguration is required. To help illustrate this point, it can be seen that both VMs in the screenshot below have the same IP address (192.168.0.20). As they are on two independent networks there is no conflict.
Whilst this blog shows a very simple example of a single VM restored from backup, the same principle applies to complex production environments consisting of multiple VMs, block volumes and database systems – indeed, however complex a production environment is, it can be restored in part or whole in to a separate-yet-identical DR network for testing purposes within the same OCI tenancy.
Having two independent networks with identical IP ranges is not without its own challenges, however, such as how to facilitate test users connecting to it, and how to allow those same users to easily determine which environment (ie. production or DR) they are connected to – the DR applications they access will appear exactly like production after all. Rest assured that all such challenges are relatively easy to address. Furthermore, some additional layers of segregation and OCI features such as the use of a separate OCI compartment specifically for DR resources, including the DR network, would be of benefit when managing the DR environment. In the worked example depicted in this blog, the production and DR networks and VMs are all created in the same OCI compartment simply to ensure the screenshots can show them together, side-by-side. In the real world, separate OCI compartments, for example, would be advised.
As shown, OCI offers several benefits and features to simplify, streamline and improve the accuracy of DR testing and at the same time all but eliminate risk.
Firstly, provisioning DR environments benefits from the same rapidity as enjoyed when creating the production environments initially. Of course, this provisioning is fast when undertaken via the OCI console but can be further improved by using tools such as the OCI command-line interface (OCI CLI) and Terraform (or indeed OCI’s Resource Manager functionality). Such tools allow provisioning and management to be scripted and automated which then facilitates another significant benefit: repeatability. Not only scripting and automating for provisioning production environments, but provisioning (and decommissioning) for DR testing also!!!
In addition to being able to rapidly provision and decommission DR test environments, your OCI tenancy can simultaneously host a DR network alongside the production network in a safe and segregated manner. Not only is it safe and segregated, most importantly it can be truly identical to the production network that contains those resources in-scope for DR testing. Those fears of duplicate IP addresses on production networks or inadvertently interfacing with production or external customers and third parties are, simply, no longer valid. Nor is the requirement to change IP addresses, hostnames or other configurations before testing can commence. The DR servers and databases can both be identical restores from backups of production without the concern of conflicts, corruption or cross-contamination.
In summary, DR testing in OCI benefits from:
- Rapid provisioning of DR environments (as one would expect from cloud!)
- Time-to-provision and repeatability further improved through automation by tools such as OCI CLI, Terraform and OCI Resource Manager
- DR network segregation within same OCI tenancy
- Zero risk of impact from DR testing to operational production systems
- Zero reconfiguration of restored systems required
- Cost minimisation
- Ability to automate DR environment availability to match scheduled DR testing thus avoiding unnecessary costs
- Rapid DR environment decommissioning
Clearly, OCI offers some not-so-obvious features and benefits for helping simplify testing backups, restores and DR. DSP-Explorer’s most recent partnership with a client to assist with their DR testing lead to a DR test environment – consisting of a segregated DR network and multiple VMs and databases restored from production backups without modification, just as described in this blog – provisioned and available for testing within a single day. Automation was then enabled to ensure that the VMs and database systems within the DR environment were available only during business hours and only when testing was scheduled to ensure the cost of these DR resources was minimised. As previously mentioned, one of the challenges with having the two identical networks (i.e.. prod and DR) was how to provide access for test users to the DR network. For this particular customer, the solution was an OCI public load balancer accessed from a small number of specific white-listed IPs allowing nominated test users to access the DR environment easily and securely. This solution won’t be appropriate for all customers or applications but is mentioned to illustrate just one relatively simple method to provide access.
In closing, backups are still very much a foundational requirement in any DR and BC strategy and so is the testing of restores and testing of DR. Cloud computing may have changed the methods but the ability to take backups and have confidence in restores and recovery procedures remains as important, if not more so than ever.
DSP-Explorer would be happy to discuss with you any of the topics in this blog or indeed any general questions you may have around data management, databases or cloud computing.